
Hacker Noon
Why Healthcare AI Fails Differently Across Specialties
When healthcare AI teams talk about failure, they talk in aggregates. Hallucination rate. Retrieval relevance score. Grounding fidelity. Average accuracy on benchmark datasets. These numbers flatten everything — every specialty, every query type, every clinical context — into a single headline metric that tells you very little about where your platform is breaking. Here's what six years of running a healthcare AI platform across multiple clinical specialties taught me: the failure modes are not universal. They are specialty-specific. An oncology deployment fails in ways that an interventional cardiology deployment does not. A pharmacy platform fails in ways that neither of those do. A primary care deployment fails in ways that make specialists shake their heads — until you understand why it's structurally hard for that specific domain. If you're building healthcare AI and evaluating it on aggregate metrics, you are missing the failures that matter most. Because the failures that erode clinician trust don't happen in aggregate. They happen in specific specialties, on specific query types, for specific reasons that are invisible until you look at them directly. Failure Modes by Specialty — Overview The diagram below maps each specialty to its distinct failure mode and engineering fix, with a common platform requirements tier at the bottom that applies across all four. \ \ Specialty Failure Modes briefly | Oncology. Velocity problem: Evidence moves faster than ingestion pipelines | Engineering fix • Event-driven real-time ingestion• Content velocity tiering by source category• Recency signals in retrieval ranker | |----|----| | Interventional cardiology. p recision problem: D ense retrieval loses specificity on narrow technical queries | * Engineering fix *• Hybrid dense + BM25 sparse retrieval• Knowledge graph: trial-to-guideline links• Specialty-specific precision evaluation sets | | * Clinical pharmacy: Interaction density.* Answers require multi-source synthesis, not single-document retrieval | * Engineering fix *• Source-type routing: monographs vs. interaction DBs• Multi-document synthesis across source types• Completeness templates for high-risk queries | | * Primary care Breadth-depth tension* Queries cross every specialty boundary simultaneously | * Engineering fix *• Cross-specialty retrieval routing• Breadth-calibrated chunking strategy• Equity monitoring across specialty categories | \ Oncology: The Velocity Problem Oncology is where I've seen healthcare AI fail fastest — not because oncology is harder than other specialties, but because oncology evidence moves faster than any other clinical domain. Clinical guidelines in oncology are updated more frequently than in almost any other specialty. New trial results change standard-of-care recommendations on timescales of months, not years. A NCCN guideline for a specific cancer type might be revised multiple times in a single year . A drug label for a recently approved therapy might be updated within weeks of approval as post-market data comes in. A healthcare AI platform with a standard corpus ingestion pipeline — weekly or biweekly batch updates, standard document versioning — is structurally too slow for oncology. By the time a guideline update makes it through ingestion, processing, review, and indexing, it may already be two or three weeks old. In oncology, two weeks is enough time for the standard of care on a specific regimen to change. \ The specific failure pattern An oncologist asks about a dosing protocol for a recently approved combination therapy. The platform retrieves the correct guideline document — but the version in the corpus is from six weeks ago, before a label update changed the recommended monitoring parameters. The answer is clinically confident and factually wrong. The oncologist catches it because she reviewed the label update herself last week. She stops trusting the platform for anything related to recently approved therapies. The aggregate accuracy metric doesn't move. The oncologist is gone. What oncology requires: Near-real-time ingestion pipelines for high-velocity source categories — event-driven, not batch Explicit content velocity tiering — sources categorized by update frequency, with ingestion SLAs matched to tier Recency signals in the retrieval ranker — not just relevance, but how recently the retrieved version was confirmed current Oncology-specific monitoring treating any retrieval of a document older than a defined threshold as a quality signal Interventional Cardiology: The Procedural Precision Problem Interventional cardiology fails differently. It's not primarily a velocity problem — ACC/AHA guidelines update on a slower cycle than NCCN. The failure mode here is precision. Interventional cardiologists ask narrow, technical questions. They are not asking "what is the guideline for managing stable angina?" They are asking "what is the current recommended FFR threshold for deferring PCI in a patient with intermediate stenosis and preserved LVEF in the context of the 2023 DEFER-2 trial results?" That is not a search query. That is a clinical reasoning question with six specific technical parameters that the retrieval system needs to match simultaneously. General-purpose dense vector retrieval fails on this class of query because dense embedding models compress semantic meaning — excellent at capturing topical relevance, poor at capturing the specific combination of numerical thresholds, trial citations, and clinical context that makes an interventional cardiology query answerable. The specific failure pattern An interventional cardiologist asks a precise procedural question. The platform retrieves topically relevant documents — all about FFR, all about PCI deferral — but none address the specific trial result she is asking about. The generated answer is topically coherent but doesn't answer the actual question. It sounds reasonable to a non-specialist. The cardiologist recognizes immediately that the platform retrieved the wrong evidence. She stops asking precise procedural questions and uses the platform only for basic lookups she could do faster herself. What interventional cardiology requires Hybrid retrieval with strong sparse lexical components ( BM25 ) that can match on specific numerical thresholds, trial names, and procedural acronyms that dense embedding dilutes Knowledge graph integration for trial-to-guideline relationships — so a query about a specific trial surfaces the guideline sections incorporating that trial's evidence Specialty-specific query understanding that distinguishes a topical question from a precision clinical question and routes them to different retrieval strategies Precision-focused evaluation datasets that test narrow technical queries, not just topical retrieval The Columbia University Irving Medical Center evaluation — where a domain-specific platform outperformed ChatGPT 4.0 by 19.3 percentage points on interventional cardiology board certification questions — was measuring exactly this failure mode. The domain-specific platform had specialty-specific retrieval infrastructure. ChatGPT was doing general-purpose retrieval. The gap was precision, not model capability. (Nanda et al., Circulation, AHA Scientific Sessions 2024.) \ Clinical Pharmacy: The Interaction Density Problem Pharmacy AI fails in a completely different way from either oncology or cardiology — and the failure is almost never about guidelines at all. The core task in clinical pharmacy AI is drug interaction and contraindication reasoning. That task requires simultaneously reasoning across multiple knowledge bases — drug monographs, interaction databases, patient population data, renal/hepatic function adjustments, specialty-specific dosing protocols — and synthesizing them into a clinically actionable answer that accounts for the specific patient context. General-purpose RAG retrieval fails here because the answer to a clinical pharmacy question is almost never located in a single document. It is assembled from multiple sources that individually don't answer the question. None of these alone answers the question "what dose of this drug is appropriate for this patient?" The specific failure pattern A clinical pharmacist asks about appropriate dosing for a renally impaired patient on a complex polypharmacy regimen. The platform retrieves the drug monograph — correct, complete, authoritative. It generates an answer based on standard dosing. The renally impaired adjustment is in a different section the retrieval system ranked lower. The interaction with another drug in the regimen is in a separate interaction database that was retrieved but not synthesized into the answer. The answer is plausible. It is incomplete in ways that could cause harm. The pharmacist corrects it mentally and files the answer away as "useful for basic lookups, not for complex patients." What clinical pharmacy requires Multi-document synthesis that explicitly aggregates evidence across source types rather than ranking documents and selecting the top result Source-type routing — routing drug interaction queries to interaction databases, dosing queries to monographs, population-specific queries to specialty guidelines Structured answer templates for high-risk query types that enforce completeness — a renally impaired dosing answer without a renal adjustment component should be flagged Pharmacist-specific feedback channels that capture "answer was incomplete" as a distinct signal from "answer was wrong" — these require different remediation Primary Care: The Breadth-Depth Tension Primary care fails differently from all of the above — and in some ways it's the hardest problem, because the failure is structural rather than domain-specific. Primary care clinicians ask questions across every clinical specialty. A primary care physician in a single morning might ask about hypertension management, diabetic nephropathy staging, a dermatological finding, a psychiatric medication interaction, and a pediatric vaccination schedule. No other specialty has this breadth of query distribution. A healthcare AI platform optimized for any specific specialty will underperform for primary care. Retrieval systems tuned on cardiology-heavy datasets will retrieve cardiology evidence well and pediatrics evidence poorly. Chunking strategies optimized for procedure-focused specialties will structure content in ways that don't match how primary care physicians look up information. The specific failure pattern A primary care physician asks about an unusual dermatological presentation in the context of a systemic condition. The platform retrieves dermatology evidence and internal medicine evidence separately but fails to synthesize them across the specialty boundary — because the corpus is structured by specialty silo and the retrieval system doesn't have cross-specialty relevance signals. The physician gets a partial answer and has to consult two separate specialty resources to get the complete picture. What primary care requires Cross-specialty retrieval that actively seeks evidence at specialty intersections, not within specialty silos Breadth-calibrated chunking strategies that structure content for contextual lookup rather than procedural precision lookup Generalist query understanding that recognizes when a question spans multiple specialty domains and broadens retrieval scope accordingly Equity monitoring across specialty categories — a primary care platform that retrieves cardiology evidence better than dermatology evidence is failing a portion of its users systematically The Common Thread Four specialties. Four failure modes. No overlap. But there is a common thread: every one of these failures is invisible in aggregate metrics. Aggregate retrieval relevance scores don't tell you that oncology retrieval is failing on recently updated documents while cardiology retrieval is failing on precision queries. Aggregate accuracy benchmarks don't tell you that pharmacy answers are incomplete in clinically dangerous ways. Aggregate quality metrics don't tell you that primary care cross-specialty queries are consistently underserved. The common engineering response to all four is the same: stratified evaluation by specialty, by query type, and by clinical task — not aggregate metrics alone. Every healthcare AI platform should be able to answer these questions for each specialty it serves: What is the content velocity tier for this specialty's primary sources, and does my ingestion pipeline match it? What retrieval strategy performs best for the precision level of this specialty's queries? What answer completeness requirements are specific to this specialty's high-risk query types? What does cross-specialty query distribution look like for this specialty, and is my corpus structured to serve it? What This Means for How You Build A single corpus, a single retrieval pipeline, and a single evaluation framework is not sufficient for a healthcare AI platform that serves multiple specialties. That doesn't mean entirely separate systems. It means: Velocity-tiered ingestion — different update cadences for different source categories matched to how fast evidence moves in each specialty Specialty-aware retrieval routing — query classification that routes to the retrieval strategy best suited to the specialty and query type Completeness templates for high-risk query classes — structured answer requirements for query types where incomplete answers are clinically dangerous Stratified monitoring per specialty — quality metrics broken down by specialty, not just aggregate, with alerts specific to each specialty's known failure modes Specialty-specific feedback channels — clinician feedback that captures the failure type relevant to each specialty, not just a generic thumbs-down \ None of this is beyond the reach of a well-resourced engineering team. All of it requires accepting that specialty-specific failure modes are real, specific, and won't surface in aggregate metrics until a clinician has already lost trust. The platform that earns sustained clinical trust across specialties is the one that was built with each specialty's failure modes in mind from the beginning — not discovered through incidents after launch. \ \
View original source — Hacker Noon ↗
Related stories
Bloomberg
BusinessJun 10, 2026 · 1 min
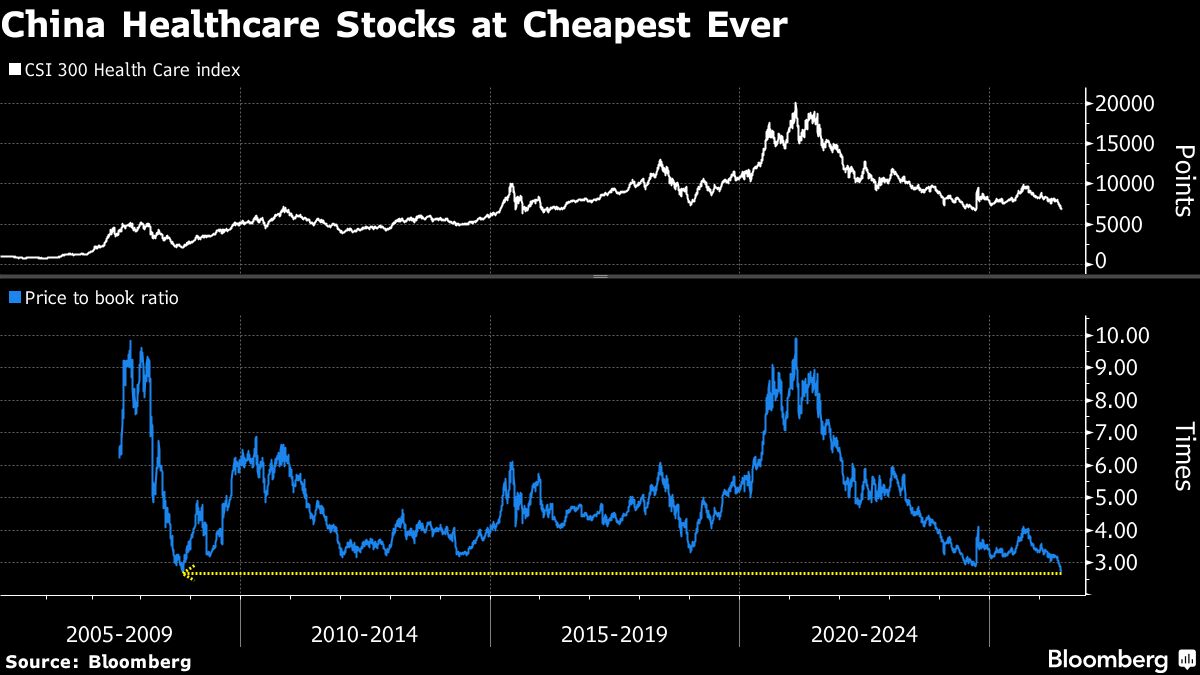
China Healthcare Stocks Fall to Record Low Valuation on AI Drain
Bloomberg

CNA
BusinessJun 9, 2026 · 1 min
AI is boosting accuracy for clinicians, Philips North America CEO says
CNA

Euronews
TechnologyJun 4, 2026 · 1 min
Microsoft and Mayo Clinic unveil a new ‘safe and trusted’ AI for healthcare
Euronews

Mexico News Daily
NewsJun 4, 2026 · 1 min
Have you used healthcare in Mexico? Take our 5-minute survey
Mexico News Daily