
Hacker Noon
Eliminating Data Latency with Event-Driven Pipelines at Enterprise Scale
Teams within every organization manage a vast volume of operational data coming from different interconnected systems. The type of data the team deals with involves org hierarchies’ info within the company, headcount details, fixed & flexible operating expenses, purchase orders intake forms, and capacity planning, etc., which are then fed into BI reporting. The raw data available for business decisions is abundant and consists of hundreds of terabytes and tens of thousands of individual files stored continuously across cloud storage accounts. The problem is not the amount of data instead it’s the availability of the data. Traditional pipelines either execute on a fixed schedule like daily, weekly, monthly or manually triggered. But this always leads with delay. By the time data becomes available and queryable, it’s already a couple of days old. Thus, all the decisions, budget review, a capacity planning, or an end-of-quarter variance discussion being done by finance leadership is based on old data. Technically the data is not wrong, it is simply late and not up to date. This article delves into production implemented engineering patterns to mitigate the above-mentioned old data issue from batch-first to event-driven architectures. Each pattern described in the article below are drawn from different domains of operation like cloud resource usage and billing management, workforce capacity planning and purchase orders intake forms compliance workflows. Overall, it represents a complete playbook to eliminate data latency and making sure live data is being processed to help in better and correct decision making which is achieved using better architecture not by bigger machines. The Problem with Batch-First Architectures Back in the days when cloud resources were expensive, refreshing ETL pipelines at scheduled time interval or running pipeline overnight made sense and was a pragmatic approach. Since last few years this has changed significantly, although the batch-first default processing of data in large scheduled groups (batches) still persists but the architectural assumption that data changes over a fixed interval of time is not valid anymore. Today, across most of the organizations, the pipelines still executes on the same fundamental architecture such as trigger pipeline at a fixed time which reads data from sources, apply data processing, load final output data to target destination or tables and notify pipelines owners for any failure (mandatory) or success (optional) through ticket, email or message. Notifying the pipelines owners with failure modes are well understood by the teams but most of the times it gets underestimated until it becomes a problem: Missing Data Dependency Check: Execution of batch pipelines on fixed schedule without checking whether latest upstream data is available leads to processing of stale data in the downstream jobs. In this case, pipelines still run successfully but leads to wrong and stale results. Data Loss Risk with Truncate and Load: Truncate and Load is most common data loading approach being used in legacy batch pipeline, but it introduces a window when data is completely unavailable. Also, in case job fails, it leads to empty table output. Downstream jobs and dashboard that executes during this window gets error out or produce no results requiring significant for the team to debug as well. No Incremental Data Processing: Legacy batch jobs generally process entire datasets rather than identifying what data has changed since last refresh. For datasets like cloud resources usage, which is at hourly grain with size of petabytes, this complete refresh process is very inefficient and cost expensive. The primary issue is not the technical debt or tooling limitations, instead it’s how the legacy batch architecture works. Considering now the source systems generate data continuously, asynchronously, and unpredictably and there is growing demand of real-time analytics insights batch architectures impose an artificial cadence limitation on reality. Event-Driven Architecture: Core Principles The shift from batch-first architectures to event-driven pipelines requires more than just replacing scheduled triggers with event-based trigger. It requires redesigning of pipeline architecture at every step like checking for data availability before processing, managing data load better, failure communication and avoiding downstream job failures or blank data in case of upstream failure. Following are five production-ready event-driven pipeline principles: Executes when Data Arrives: Rather than executing pipeline on fixed schedule, pipelines should run when there is new source data, files or database change events Separate Data Transformation from Raw Ingestion: The best practice is to preserve raw data exactly as it arrives and build a transformation in separate layer. Storing raw data as is helps in making sure in case when something goes wrong in downstream jobs. Design for Failures before Success: While designing pipeline, consider all possible cases which could lead to upstream failure like bad data, data being not up to date or data arriving late etc. At design time itself pipeline must define exactly what would happen in case of upstream failure and how that’s being tackled Automate Schema Changes: It’s quite common to have a schema change in the sources systems. The pipeline should be designed such that it can automatically detect the new columns, handle data type changes and update download stream catalog without manual intervention. Cloud based pipelines like AWS Glue Crawler is one of the good examples here which auto-manages schema changes from upstream input files. Track Pipelines Performance and Health: Monitoring pipeline performance and health is essential to make sure everything is executing as expected so that in case of any issues in pipeline, tech team can take necessary actions to fix it before downstream users notice or downstream jobs get impacted. The above-mentioned principles are the direct response to repeated failure modes encountered in the production data architecture pipelines. Each of the patterns described below implements these principles in a different operational context. Pattern 1: Incremental Processing of Petabyte Scale Data Domain: Cloud Infrastructure Resources Usage Billing Data Nowadays, all companies across the globe are using cloud resources like AWS, Azure, Google Cloud Platform (GCP) etc. to manage their databases, applications, infrastructure, computing and pipelines which generate cloud resources usage data continuously at hourly grain. The data gets collected as hundreds of terabytes of parquet files which requires processing every day. The main challenge with dealing such a large amount of data is not about reading the data, it primarily about reading only new data without reprocessing what has already been transformed. While working on this myself, my initial approach generally was to build a pipeline with full-scan which read and processed all the source data, applied transformation and loaded to output tables. But, this approach was not sustainable, and compute cost was significant as it processed hundreds of terabytes data and tens of thousands of files taking 4-5 hours per execution. And as the data grew further, the execution time and compute cost increased further. To resolve this, I implemented four optimization techniques in AWS Glue: Bookmark-based incremental processing: With bookmark**,** the transformation job maintains a persistent context tracking exactly which source files have been processed in each prior run. Subsequent executions read only files that have not yet been transformed, regardless of partition structure or arrival time. This single change eliminates the core inefficiency of full-scan architectures. Broadcast joins on dimension tables: Smaller datasets like account hierarchies, category mappings, organizational structures etc. which gets joined with main granular dataset are broadcast to all worker nodes rather than shuffled across the cluster. Shuffle joins on large granular datasets are the most common hidden cost driver in Spark-based pipelines. Broadcasting small tables to all executors eliminates this entirely. Partition predicate pushdown: With this the job passes partition predicates to the storage layer, allowing the file system to skip irrelevant directories entirely and avoid reading entire storage locations. A job targeting a specific billing period reads only the relevant partition folders. This helps in reducing the storage scanning cost significantly. Bounded file processing per run: This means to cap the total numbers of files at each execution. In my case I set it up approximately 450 files. This helps in creating a predictable execution time and memory utilization regardless of upstream delivery bursts. For example, if 2,000 new files arrive overnight, the pipeline processes them in sequential in respect to the 450 files bounded batches rather than attempting to handle the full burst in a single run. Overall, it resulted in reducing execution time from 3.5 hours to ~30 minutes, compute resource consumption reduced from 800 DPUs to 120 DPUs which was an 85% reduction in infrastructure cost. The key architectural insight is that incremental processing, partition pruning, and bounded execution are multiplicative rather than additive. Together, these optimization techniques help in transforming an unpredictable, expensive full-scan job into a predictable, cost-efficient incremental pipeline where each run processes only what is genuinely new. For comprehensive details on AI-driven optimization techniques applied to petabyte-scale cloud resource data, including predictive cost modeling, anomaly detection, and multi-region workload migration strategies, refer to my detailed published work: " Beyond Cost Reduction: AI-Driven Cloud Resource Optimization at Petabyte Scale " (ACM Communications, 2025). Pattern 2 — Dynamic Schema Evolution for Multi-Template Data Domain: Workforce Capacity Planning For workforce capacity planning, input from many organizational units in the workforce group across the enterprise is coming in at the same time. While there are many attempts to create a standard input template, in the end each team will fill out their capacity data in the template that they manage within their organizational unit. Thus, instead of a handful of different file formats (e.g. CSV, Excel, JSON) with a handful of different versions (e.g. current, prior quarter prior), there are dozens of file formats with hundreds of different versions as the templates are managed and updated on a quarterly basis. In the process, fields are often renamed from one organizational tracking metric to another, and the data is formatted differently from one template to another. Traditionally, a pipeline’s operation is based on the assumption that the pipeline is designed to operate against a fixed schema contract. If that contract changes, then the pipeline fails. For example, a simple database table with three columns of A, B, and C, a simple pipeline is written to read against the table with columns of A, B, and C. However, when a 4th column D is added to the table, or when column B is renamed to column M, the simple pipeline above fails. When operating with dozens of templates (all submitted and managed by upstream teams) all changed out independently by many different teams on a quarterly basis, schema changes are not an edge case, they are the normal operating model of the process. The pipeline architecture for this domain uses AWS Step Functions to orchestrate a sequence of event-driven stages, each designed for a specific schema-handling responsibility: S3 event-triggered detection: In this case S3 event-triggered detection of new files in the S3 landing zone and the subsequent Step Functions processing of these files within seconds. There is no need for polling or a scheduled run of the pipeline as the event-driven architecture processes the data as soon as it is available. Lambda function to perform data preprocessing and normalization: To better process data with the Glue Crawler for schema discovery, the first step in processing these incoming data sets would be to perform data normalization and encoding. This is an ideal process step to perform prior to discovering a new schema to best enable the Glue Crawler to obtain the largest amount of value from the data. Automated schema discovery: The Glue Crawler automatically discovers the schema of the normalized data stored in the S3 landing zone by the lambda function. The Crawler updates the data catalog automatically, new columns are discovered and the data engineering team does not need to alter the code of the ETL jobs in order to include them in the output data. Sleep/Polling for Crawler Status: Crawler is an asynchronous component, which means Step Functions has to poll for the status of the Crawler until it is ready. If Crawler is running, Step Functions will wait for a certain amount of time and then check again. If Crawler fails for some reason, Step Functions will automatically time out. Schema-aware ETL execution: The ETL process then loads the data and only reads the column definitions from the updated data catalog at runtime. As a result, all newly discovered columns by the crawler are automatically included in the output of the ETL process without any code changes. Reconciliation and discrepancy alerting: When all the data from all of the various templates has been processed through the ETL jobs for example, the resulting data is then checked for discrepancies between the records from the various input templates. For example, the system could look for the total number of records, total sum of measure attributes etc. In cases where discrepancies are found, the system automatically raises alerts/tickets/messages and send to the appropriate data owners to investigate/resolve the discrepancies as quickly as possible to avoid any negative impact on the users and other downstream consumers of the data. Diagram-1: This dynamic and programmable data model also means there is zero maintenance of the data’s schema. Whenever there is change in schema, it will appear automatically in the relevant output of all of the subsequent ETL jobs in the next pipeline execution without any involvement from data engineering team. Treating the schema as a dynamic as opposed to a static contract allows for much easier to manage data engineering systems in multi-contributor environments. Overall, schema rigidity is a choice that can lead to many fragile points in the pipelines. Pattern 3 — AI-Augmented Pipeline Operations Domain: Governance Compliance Workflows Above two patterns focus on core problems in data engineering: data reliability and latency to deliver well-structured data to analysts and business users. But once data platform delivers reliable, well-structured data to its consumers, it is very useful to layer AI on top of it and use it for analysis, prediction, automation, etc. This pattern discusses of using AI on top of a trustworthy data platform is particularly powerful when used for workflow governance within an enterprise organization. A typical workflow for a form of intake within an organization consists of several steps and the following elements: first an intake form is filled out by a user (such as a request or application) and then that intake is reviewed against the various rules set by the business owner of that process (for example, date, values on the form, etc.). If during that process of validation by rules any issues are found then the owner of the intake (the user that filled out the intake form) would be contacted by the approver in the organization. Then as the approver goes through all the steps of approving or rejecting an item for which an intake form was submitted (the process) follow-up by email for each step of approval or rejection is typical to alert other members of status changes for items that have been put into the system for processing. Using AI capabilities along with the event-driven data pipeline allows reviewer to only needs to review the detail provided for the submission rather than manually validating it, which greatly facilitates the review and above all also accelerates the decisions made by the reviewer: Automated compliance validation: The AI integrated with the reliable data platform automatically detect whether the incoming data from intake forms complies with a predefined set of business rules (format, reason, value, etc.) for the compliance. This AI-powered validation is embedded into the data-driven approval workflows as an automated compliance check. Automated compliance validation automatically moves valid submissions into the approver’s queue for review, with all details pre-populated and thus easily consumable by the human reviewer. Invalid submissions are optionally flagged for the approver for further action. · Conversational data access: Users are able to access data of value to them without having to know how to access data via a complex set of data structures. This means that users can simply ask a question of the system, such as “Show me all the submitted intake forms that are pending approval in the last 5 days”. The system then converts the users’ question into a set of operations on the output tables created from the ETL jobs, and returns the resultant structured data to the user. A critical architectural consideration when adding AI to a data pipeline is to recognize that AI does not replace good data engineering; it augments it. Thus, if you add an AI agent to your batch pipeline that runs every 24 hours, you are going to get very stale information and lose the trust of the people who are depending on you to provide them with good-quality data. But if you incorporate that very same AI agent into an event-driven pipeline that is refreshing the data on an hourly basis, then you can really start to use that to accelerate your operations and provide reliable answers to people. So, the essence is first you build a good data infrastructure, and then you add the intelligence on top of it. Architecture Comparison The table below summarizes the operational difference between traditional batch and event-driven architectures across production-relevant dimensions: Table-1: | Dimension | Traditional Batch | Event-Driven | |----|----|----| | Data Availability | 24–72 hours after generation | Seconds to minutes | | Failure Detection | Hours or days (customer-reported) | Immediate (automated alerts) | | Schema Changes | Manual intervention, pipeline breaks | Automatic discovery and cataloging | | Cost Model | Always-on compute, pay for idle | Pay-per-event, serverless | | Downstream Impact | Cascading failures (40+ jobs affected) | Contained (quality gates block propagation) | | Recovery Approach | Manual investigation and rerun | Documented procedures + automated retry | | Data Loss Risk | High (truncate-and-load) | Low (staged loading with atomic swaps) | Conclusion Overall, adopting event-driven pipelines is not a technical upgrade; instead, it’s just a change in the execution process on how a data pipeline is supposed to perform. Batch-first architectures ensure that data gets processed, whereas event-driven pipelines guarantee refreshed, completed, and validated data to the end users. With event-driven pipelines, the data latency reduced from days to minutes which impacts the organizational behavior such that financial teams don’t analyze stale data anymore, leaders can ask questions at the meeting, not to wait for answers till the next reporting cycle and insights can be based on current numbers not the projections. The patterns discussed in this article address different challenges and failure modes across different used cases common in any industry. These patterns are neither mutually exclusive nor sequential but rather overlapping. The day-to-day data engineering work involves implementing these patterns while balancing data complexity against latency and cost against performance. The importance is not in any single technique, instead it’s in the aggregation of design choices that make data available on time correctly, and accurately. \
View original source — Hacker Noon ↗
Related stories

TechRadar
TechnologyJun 24, 2026 · 1 min
I made a massive mistake when buying Red Dead Redemption 2 — Here's how to avoid the same trap with GTA 6
TechRadar

Indian Express
TechnologyJun 24, 2026 · 1 min
Amazon Prime Day 2026 India: Dates, deals, AI shopping tools, and more
Indian Express
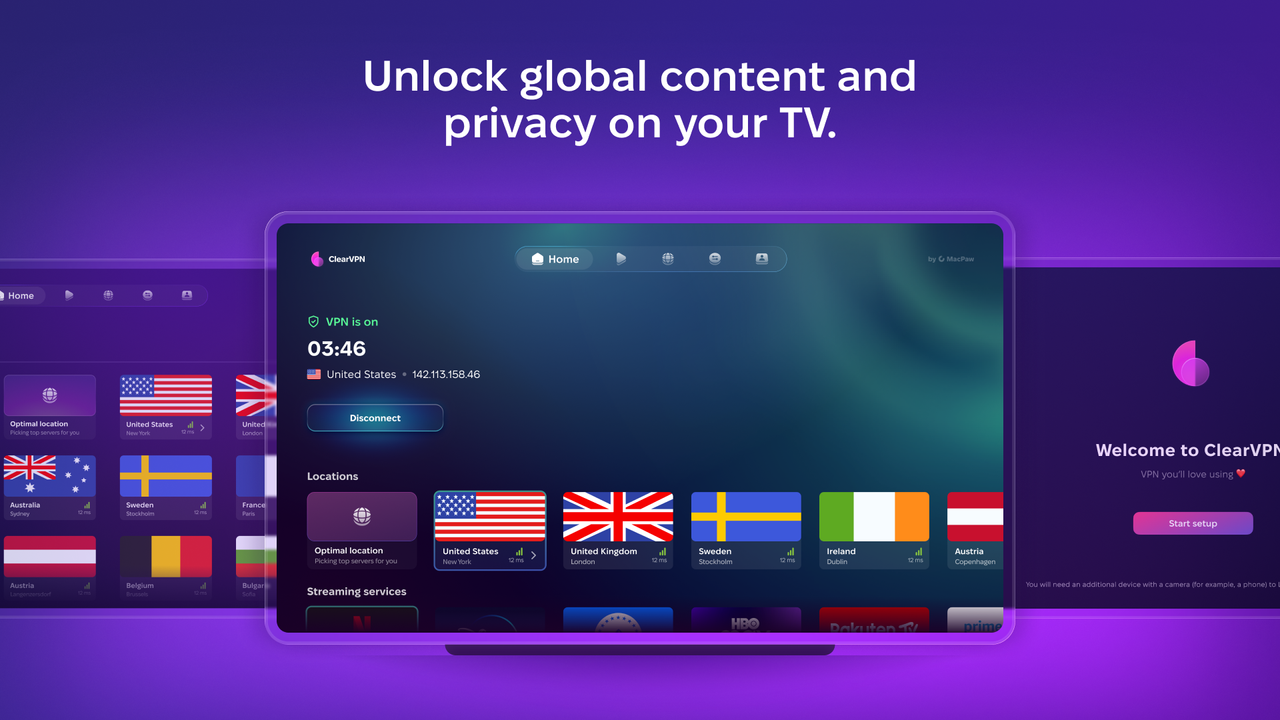
TechRadar
TechnologyJun 24, 2026 · 1 min
MacPaw brings its 'privacy-first' ClearVPN to the biggest screen in your house
TechRadar

TechRadar
TechnologyJun 24, 2026 · 1 min
Star Fox isn’t the most exciting remake, but it’s still a fun time
TechRadar