
Hacker Noon
The Real Bottleneck Isn’t Writing Code. It’s Trusting It.
We got what we asked for. For years, software teams were told to move faster. Write faster. Ship faster. Close tickets faster. Reduce cycle time. Improve velocity. Automate the boring parts. Remove friction from delivery. Then AI coding assistants arrived, and suddenly the blank file was not blank anymore. A developer could describe a function and get a first draft. Ask for a test and get one. Ask for a YAML file, a mock service, an API client, a refactor, a migration script, a quick explanation of a stack trace. The machine would produce something. Usually something that looked pretty good. When you review the pull request you find strange things. The code is not obviously wrong. In fact, that is the problem. It looks fine. The naming is reasonable. The pattern is familiar. The comments are clean enough. The tests pass, at least the tests that exist. Nobody has the immediate satisfaction of saying, “This is garbage.” It is not garbage. It is worse than garbage. It is plausible. Plausible code is expensive. Bad code announces itself. Plausible code asks to be trusted. That is where the bottleneck has moved. Not to writing code. To trusting it. I started thinking about this more seriously while working around enterprise API systems. Not because AI suddenly wrote some monster piece of code and destroyed everything. Real life is usually less dramatic and more annoying. The scary changes are often small. One response field. One retry condition. One validation rule. One tiny adjustment to how a path is forwarded. One “safe” cleanup in a proxy or service that nobody expects to matter. Think a downstream consumer depends on a field that was never officially documented or an old integration expects a path suffix to behave a certain way because somebody fixed a production issue two years ago and the fix became tribal knowledge. A retry is harmless for a read operation but dangerous in a payment or dispute flow. The code passes tests because the tests describe the world everyone wishes they had, not the one actually running in production. This is the part AI does not see. Honestly, many humans do not see it either until something breaks. Enterprise software is not just code. It is history. It is old decisions. It is half-written documentation. It is one team’s assumption hiding inside another team’s dependency. It is the Slack message that never became a ticket. It is the incident from last year that everyone remembers vaguely but nobody wants to reopen. A coding assistant can generate a clean implementation inside a file. The risk may live outside the file. That should make us slower in a useful way. Instead, a lot of teams are becoming faster in a dangerous way. More code, more pull requests, more “AI helped me finish this in 20 minutes,” more dashboards that make leadership feel like the engineering machine is finally humming. But nobody gets a clean dashboard for reviewer anxiety. Nobody puts “time spent wondering whether this generated code is subtly wrong” in a sprint report. Because that is real work now. When I review AI-assisted code, I am not only reading what is there. I am trying to reconstruct how it got there. Did the developer understand the generated logic or just accept it because it passed? Did the AI infer a business rule from a vague prompt? Did it choose a library because it was right for our environment or because it is common on the internet? Did it handle the one edge case our system always has, the one that never appears in examples? This is tiring work. It is also the work that prevents incidents. The uncomfortable thing is that AI can increase the amount of code entering the system without increasing the amount of judgment available to inspect it. That imbalance does not show up immediately. For a while, everything looks better. People close tickets. Pull requests move. Delivery charts improve. Then the cleanup starts. A bug appears in a place that “should not have changed.” A service behaves differently under partial failure. A customer-facing flow breaks only for one type of account. A dependency scan finds something late. A rollback takes longer because nobody fully understands why the generated code chose that approach. The team spends three days recovering the confidence they supposedly gained in three hours. This is why I do not trust AI productivity claims that stop at speed. Speed is the easiest part to measure and the easiest part to exaggerate. Lines of code, commits, completed stories, PR count - these are cheap metrics. They tell you that activity happened. They do not tell you whether the system became safer, clearer, more maintainable, or easier to operate. Sometimes more code is not progress. Sometimes the best engineering decision is to delete the clever thing, keep the boring thing, or not build the thing at all. AI is not very good at that kind of restraint unless the human brings it. That is where software engineering starts to look less like code generation and more like judgment under uncertainty. The machine can draft. The engineer has to decide whether the draft belongs in the system. And no, this does not mean teams should ban AI coding tools. That argument feels tired already. The tools are here. They are useful. I use them. Many developers use them. The question is not whether AI belongs in software development. The question is whether our engineering habits are mature enough for the amount of code AI can now produce. Right now, in many places, I do not think they are. Requirements are still too vague. Tests are still too happy-path. Code review is still too overloaded. Platform standards are still too optional. Documentation is still treated like charity work. Ownership is still fuzzy when something crosses team boundaries. AI did not create those problems. It exposed them. A vague prompt is just a vague requirement with better marketing. If the task says “add retry logic,” that is not enough. Retry what? On which errors? How many times? With what timeout? What happens if the operation is not idempotent? What gets logged? What alert fires if retries spike? What happens to the customer while the system is being “resilient”? That last word gets people into trouble. Resilient for whom? The service? The customer? The downstream system? The audit team? AI will happily fill in the blanks. That is the danger. It fills them in with something reasonable-looking. Good engineering teams cannot let the model guess the parts the business refuses to specify. If AI-assisted development is going to work at enterprise scale, specifications have to become sharper. API contracts need to be real. Data contracts need to be real. Error handling cannot be an afterthought. Security constraints cannot live only in someone’s head. Acceptance criteria need to describe failure, not just success. The same goes for testing. Unit tests are nice. I like unit tests. But a unit test can also be a small ceremony where we prove that our own assumptions are internally consistent. Production does not care. Production cares about the weird account type, the delayed message, the duplicate request, the downstream timeout, the partially migrated customer, the old mobile client still sending the old payload, the permission boundary nobody tested because the demo user was an admin. AI-generated code does not deserve less testing because it was generated quickly. It probably deserves more testing because nobody lived through the act of writing every line. That sounds harsh, but I think it is fair. When a human writes code slowly, some understanding is built during the struggle. When AI produces the first version instantly, the struggle moves to review. Skip that struggle and you are not saving time. You are borrowing risk. Code review has to change too. A normal pull request often carries an invisible assumption: the author knows why the code is shaped the way it is. With AI-assisted work, that assumption is weaker. The author may understand the goal but not every generated detail. That is not a moral failure. It is just a new reality. So for risky areas, reviewers need more context. Was this generated? What was changed manually? What alternatives were rejected? What tests cover the ugly cases? Does the author understand the failure modes? If this touches authentication, payments, regulated data, infrastructure, or a customer-impacting API, I want more than “LGTM” energy in the review. And ownership has to be brutally clear. AI cannot carry a pager. AI cannot join a bridge call at 2 a.m. and explain why a retry loop doubled traffic to a downstream dependency. AI cannot write the postmortem with the right amount of honesty and political tact. AI cannot look a customer in the eye. AI cannot answer an auditor. The team owns the code. More specifically, the person who merges it and the organization that allowed it to be merged own it. That means nobody should merge AI-generated code they cannot explain. Not perfectly. Not academically. But well enough to tell another engineer what it does, why it is safe, where it might fail, and how they know. There is another group that matters more now: platform engineering. If every developer uses AI to generate their own version of service scaffolding, logging, deployment config, auth checks, and retry behavior, congratulations, you have not accelerated engineering. You have industrialized inconsistency. The best use of platform engineering in the AI era is not to become the department of “no.” It is to make the safe path so easy that generated code naturally falls into it. Approved templates. Golden paths. Internal libraries. Secure defaults. Observability built in. Deployment guardrails. Dependency policies. Contract testing as a default, not a lecture. AI should not be pulling random patterns from the internet when the company already has patterns it trusts. This is where the better teams will separate themselves. Some organizations will use AI to create more code and call that transformation. They will have impressive numbers for a while. More output. Faster tickets. Bigger demos. Then they will quietly pay for it in review fatigue, brittle systems, security exceptions, and production surprises. Other teams will be less flashy and more serious. They will use AI, but they will also tighten the system around it. Clearer specs. Stronger tests. Better review habits. Platform guardrails. Real ownership. Better incident feedback loops. They will not ask, “How much code did we generate?” as the main question. They will ask, “How much of this code can we actually trust?” That is the question I think matters now. Not because trust sounds noble. Because without it, AI-assisted development becomes a factory for uncertainty. A software team does not win by producing the most code. It wins by producing code that can survive contact with users, failures, audits, traffic spikes, old integrations, angry customers, tired on-call engineers, and all the strange little realities that never appear in a clean demo. AI can help us move faster. I am not arguing against that. I am saying speed is not the finish line. The real work starts when the code looks done. \
View original source — Hacker Noon ↗
Related stories

TechRadar
TechnologyJun 25, 2026 · 1 min
Don't be tempted by the lowest-ever Nintendo Switch Prime Day discount, I'm a gaming editor and the Switch 2 is still…
TechRadar

TechRadar
TechnologyJun 25, 2026 · 1 min
Currys is a goldmine for back-to-school and business laptop deals from Asus, HP, and Lenovo
TechRadar

Lovin Malta
TechnologyJun 25, 2026 · 1 min
European Commission Releases First €3.2 Billion Under €90 Billion Ukraine Loan
Lovin Malta
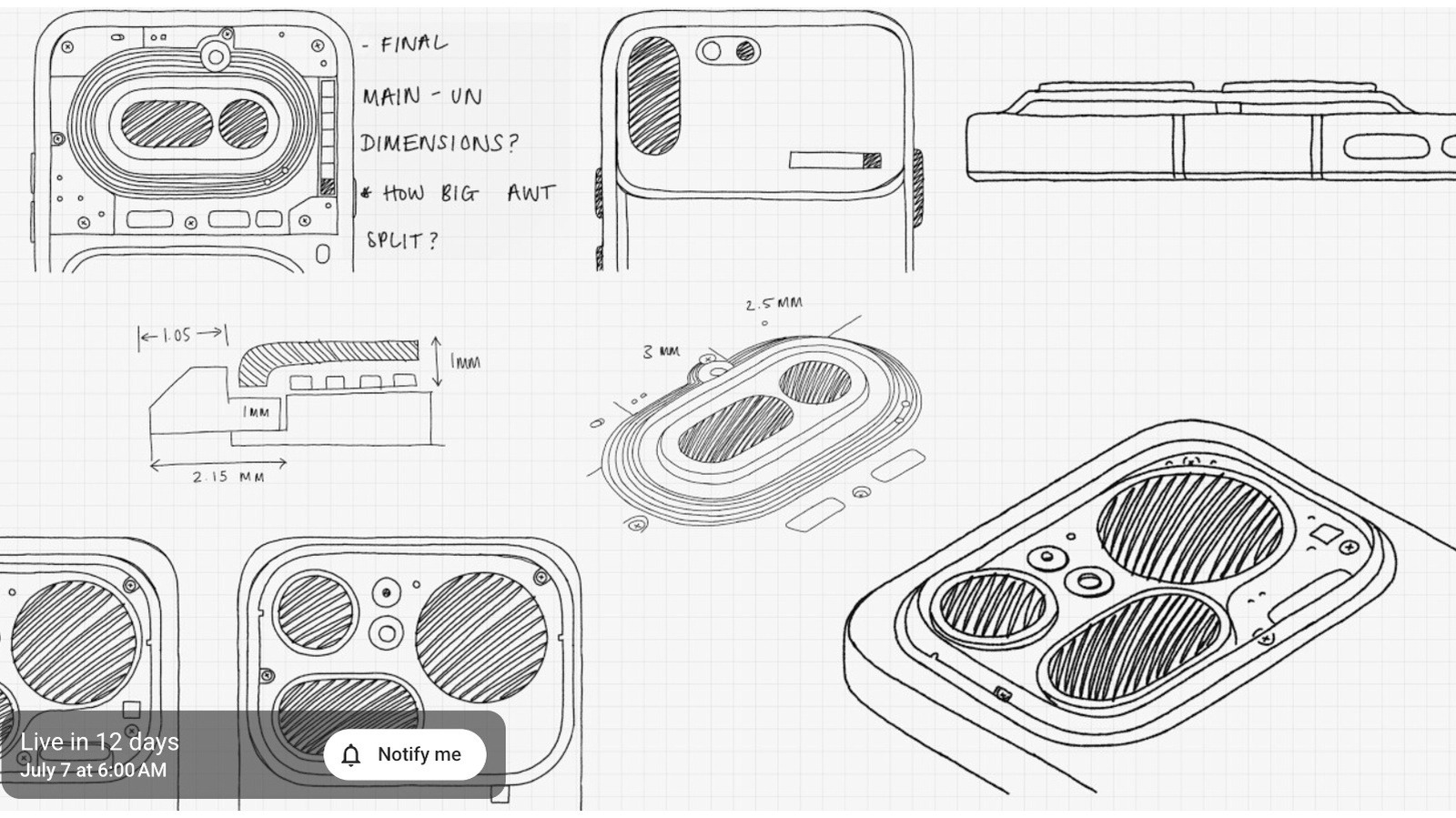
Engadget
TechnologyJun 25, 2026 · 1 min
Nothing teases the Phone 4b, launching on July 7
Engadget